2月24日⚇,硅谷美国神经技术公司C. Light首席技术官(CTO) 兼联合创始人Joe Xing博士应邀访问我系并做客第520期“凯发K8学术论坛”。邢博士面向全系师生作了题为“生成式人工智能与大语言模型在医疗健康行业中的应用”的学术报告。本次学术论坛由张黎明副教授主持🖨,大约20名师生参加🖋。

大语言模型(LLM)是一种人工智能驱动的算法框架,最初旨在捕捉文本或语言数据的数学表示,这些表示会随着时间的推移自然演变。正如单词和字符遵循结构化序列来编码意义一样,许多形式的医疗和医学数据也表现出固有的时间相关性🙎♂️🎮。例如🚴🏿👅,DNA(遗传学和基因组学)👨🏻🎤、RNA(转录组学)🤹🏼♀️、蛋白质序列(蛋白质组学)🙋🏽♂️🧌、蛋白质功能(跨组学)以及医学成像视频序列数据,如fMRI(功能性磁共振成像)、4D CT(时间分辨CT)📇🚶➡️、dPET(动态PET)🎦、X射线视频成像(血管造影)和眼动追踪序列(注视眼动)。本次报告探讨了大语言模型和生成式人工智能在医疗和健康应用中的最新进展,涵盖模型架构🪝、训练方法👌🏿🖖🏼、推理性能以及潜在的工业应用。
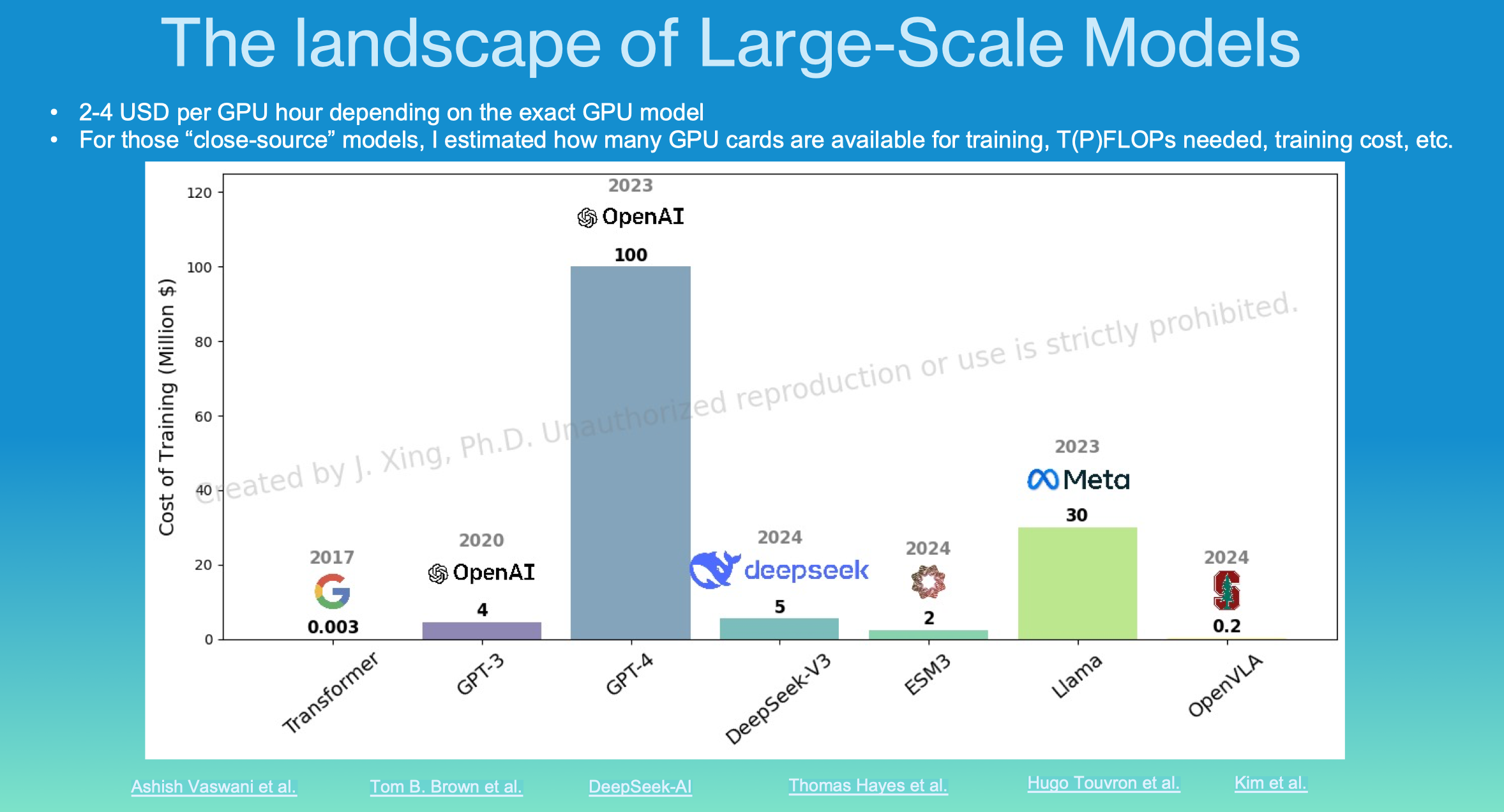
邢博士首先横向对比了目前主流的通用及专业大语言模型(Transformer,GPT-4,DeepSeek-V3,ESM3,Llama,OpenVLA等)的训练成本、训练带宽、模型复杂度📝、训练数据规模🚶🏻♂️➡️、训练用时🎐、每词元(token)成本与每参数成本等指标。他指出过去大模型领域具有的高资本门槛🚜,在DeepSeek横空出世后被打破。得益于开源社区的贡献,邢博士认为如今小型初创公司也可能能在大模型领域做出贡献🏄🏿♀️。
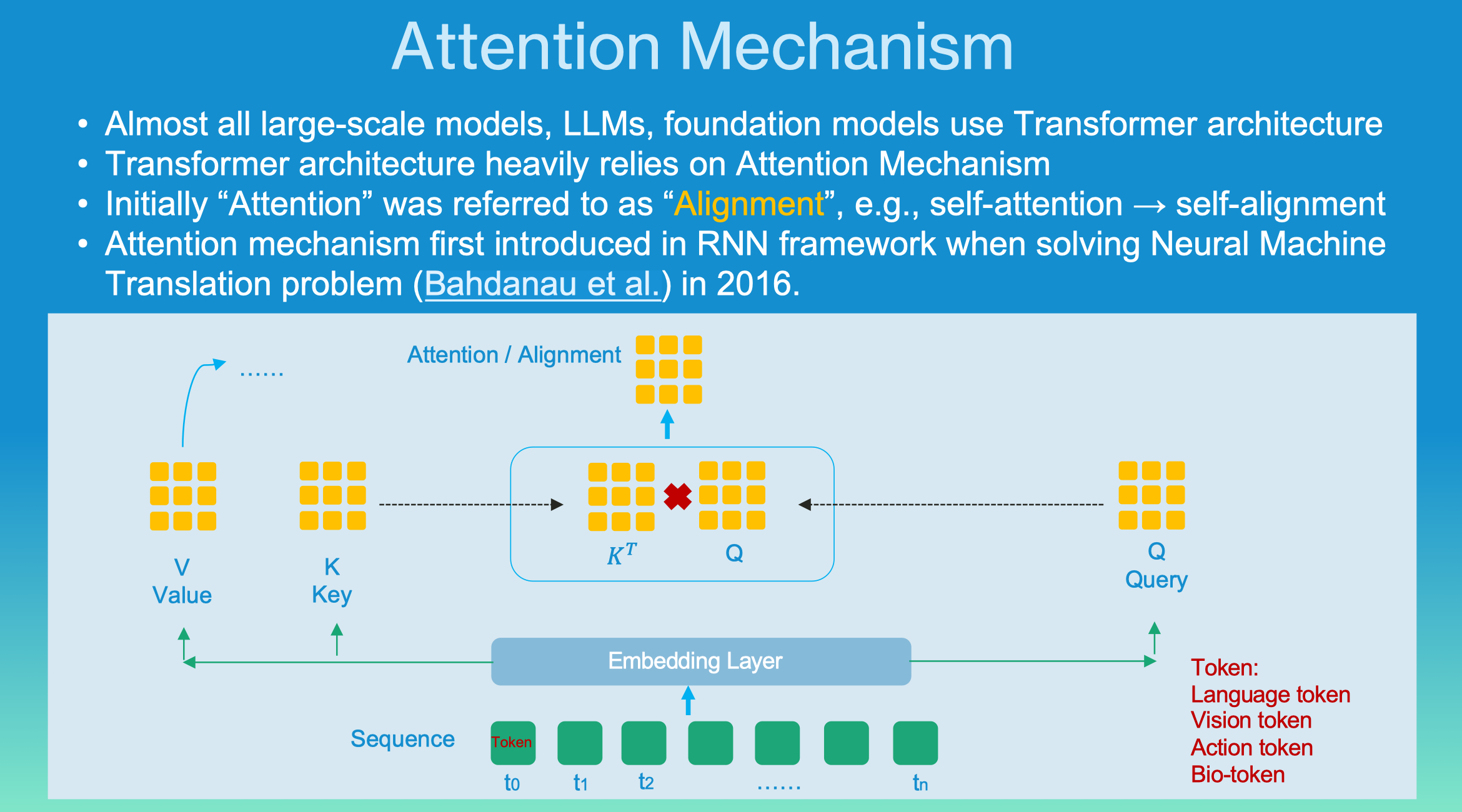
随后🎩🧗♀️,邢博士简明介绍了大语言模型中至关重要的Transformer算法和注意力机制(Attention Mechanism),并且比较了Transformer算法和传统的RNN🧡、CNN算法的实际应用和优劣。他通过比较人脑相比大模型在处理几类代表性问题的时间复杂度上的优越性,指出目前的通用大语言模型在回答简单的事实问题时🧑🏽🌾,由于过度使用认知控制(Cognitive Control)🏂🏻,极大降低了思考效率,很可能存在巨大的优化潜力。
最后,邢博士介绍了大模型的一些典型应用及其基本原理。比如使用ESM3来快速预测蛋白质结构以及提高新药开发效率,使用BiomedCLIP来辅助医生阅读医学影像,并介绍了C.Light公司开发的基于视网膜眼动原理进行疾病诊断与早期预防的医学产品Retitrack的临床效果与基本原理🥗。

注:
Joe Xing博士在雪城大学(Syracuse University)和欧洲核子研究中心(CERN)获得了物理学博士学位👨👦👦,随后加入斯坦福大学,担任全职科学家(Permanent Role Staff Scientist)。邢博士曾担任一家早期电动汽车(EV)初创公司的首席AI科学家(Lead AI Scientist),该公司后发展为估值数十亿美元的独角兽企业🪻,并于2018年成功上市。随后,他在一家德国汽车品牌担任人工智能与自动驾驶总监(Director of AI and Autonomous Driving),并自此创办了多家初创企业,其中部分公司成功入选Y Combinator孵化计划。目前🌙,邢博士担任C. Light Technologies, Inc. 的首席技术官(CTO)兼联合创始人。C. Light Technologies 是一家神经技术(Neurotech)与人工智能(AI)初创公司,致力于开发眼-脑连接的相关解决方案☂️🤸🏼♀️,以用于神经疾病的预测性和预防性护理🚾。
